I can’t believe I haven’t blogged this out, yet. I’ve been building chatbots for clients for years now, and presenting to the tech community on the topic at least as long.
For a while, I was doing “Bot in a Day” workshops, all over the country. Held at Microsoft Technology Centers in places like Boston, Reston, Philly… I just realized the last one I did was over a year ago, now, in Irvine, California.
The reason we don’t need to do the day long workshops anymore is because everything we did (and more!) in “Bot in a Day” can now be done reliably and repeatably in minutes… We do this using the latest iteration of the “Enterprise Template”, now known as the “Virtual Assistant Template”.
Ok, so the one-time setup can be a bit longer than an hour… but that’s (mostly) one time. If you are a C# dev, especially in the ASP.NET Core space, you probably have most of the tools installed already, anyway.
Anyway, I’ve been doing variations on this “Bot in an Hour” theme, using Virtual Assistant Template, all over New England, and will soon be taking it on the road to Washington DC, where I’ll be doing the shtick for Ignite the Tour in February 2020.
So the Virtual Assistant Template is a very quick way to build out some meaty bones of an enterprise-grade chat bot, especially in C# (though a TypeScript version is also available).
I won’t try to do what its own documentation does well, at this point. Rather, I’ll point you to that documentation.
Here’s my presentation slides from Boston Code Camp, which was on November 23rd, 2019. It’s more complete than the stripped down version I presented as a workshop at Global AI Bootcamp 2019 today (December 14th) at MIT.
In addition to the “Welcome to the Virtual Assistant Template” presentation for Ignite the Tour, I’ll be doing a similar presentation for Granite State NH .NET Devs on December 19th at the Microsoft Store in Salem, NH.
As many folks in my community may already be aware, I’ve been building chatbots with my team, using the Microsoft Bot Framework, a lot lately. In doing so, we’ve encountered a common issue across multiple clients.
Cognitive Content Crisis
While many peolpe are worrying about lofty issues around artificial intelligence like security, privacy, and ethics (all worthy to be sure), I’m considering something more pragmatic here. Folks go into a cognitive agent build without considering content, how it relates to AI and AI development, and how to manage it. While some of my clients with more mature projects have taken a crack at resolving this issue with custom solutions, these custom solutions are often resource intensive, fail to consider all the business requriements, and end up becoming an unnecessary bottleneck to further development. Worse, waiting till a project phase-2 or phase-3 to address it compounds the trouble.
Sadly, there’s often an enterprise content management system (ECMS) in place that could be used, instead, right from pre phase-1. With a reasonable effort, a well-featured existing ECMS can be customized along side your build out, saving a massive effort later.
The Backstory
If you check out that Microsoft Bot Framework website, one of the first things you’ll notice is that building conversational agents is a process that cuts across a number of development disciplines… and the first one that typically gets highlighted is Artificial Intelligence.
Artificial Intelligence around conversational agents could include anything from visual identification & classification to moderation, sentiment analysis, and advanced search, but it predominantly revolves around language tools… especially LUIS, QnA Maker, Azure Search, and others.
At this point, it helps to think about what Artificial Intelligence is. Artificial Intelligince is about experience. In a conversational artificial intelligence, that content is human readable, social, and web like. Experience is content…. Conversational content.
In fact, it’s almost web like. A user typically opens a chat window (which correlates a bit to a browser) and types an utterance (query). The bot catches such utterances, and depending on a number of factors of origination, data state / context, identity, and authorizations, generally produces a text based response.
Getting More Specific
In the case of a bot designed to coach folks with a chronic disease, for example, a user might ask a bot “Can I eat chocolate cake?”. The bot gets this query, and parses it into language elements… which looks something like “can I eat” as an ‘intent’, and “chocolate cake” as an entity. The bot then brings in a rules-set described by conditions it knows about the user (what disease(s) are being managed), and what the bot knows about the users current state (perhaps the blood glucose level if they’re diabetic). Based on the conditions against the rules, the response must be produced. If you have a sophistocated bot, you might have a per-entity response… Take a response like “OH, chocolate cake is wonderful, but your blood sugar level is a bit high right now. Unless you can find something in a low-carb, sugar free variety, I wouldn’t recommend it, but here’s a recipe you might try instead.” That content (including the suggested recipe) must be authored by subject matter experts, moderated by peers, approved (potentially by regulatory and maybe even legal teams), tagged to match the rules engine expectations… much like web content.
Also note, the rules engine itself is also content in a sense. In order to let subject matter experts have a say in tweaking and tuning responses, (what’s a high blood glucose level? What’s too much sugar for a high blood glucose level, et al.) These rules should be expressed as content a subject matter expert could understand and update.
Another common scenario we’re seeing is HR content. Imagine you’ve got a company that produced an HR handbook every year. Well, actually, you’re a conglomerate that has a couple dozen handbooks, and each employee needs answers specific to the one for their division… Not only do you have to tag the contet by year, but by division, and even problem domain. (Imagine trying to answer the question “what is my deductible?” It’s easy enough for a bot to understand that this relates to insurance provided through benefits. The answer might be different depending on whether you mean the PPO or the PMO medical plan… or is that a dental plan question? What about vision? They probably mean this year. Depending on the division they’re a part of (probably indicated by a claim in their authorization token), they might have different providers, as well.
Back to Development
In the development world, not only do you have the problem domain complexities present, but you also have different environments to push content to… the Dev environment is the sandbox a coder works in actively, and it’s only as stable as the developer’s last compile. Then there might be environments named things like DIT, SIT, UAT, QA, and PROD. To do things right, you should update content in each of these environments discretely… updating content in QA should not affect content in SIT, UAT, or PROD.
Information Architecture
Information architecture (IA) is the structural design of shared information environments; the art and science of organizing and labelling websites, intranets, online communities and software to support usability and findability; and an emerging community of practice focused on bringing principles of design, architecture and information science to the digital landscape.[1] Typically, it involves a model or concept of information that is used and applied to activities which require explicit details of complex information systems. These activities include library systems and database development.
We’ll add artificial intelligence cognitive models and knowledge bases, especially for conversational AI, to that definition. Note that some AI applications need big data solutions. Most ECMS products are not big data solutions.
Enterprise Content Management Systems
There’s a lot of Enterprise Content Management Systems out there, many of which would be suitable for the task of handling the needs of most conversational AI content management systems.
My career path and community involvement causes me to lean toward SharePoint. If you break down the feature set, it makes sense.
Ability for SMEs to manage experience data easily without lots of training to understand create/read/update/delete (CRUD) operations
Ability to customize content type structures
Ability to concurrently manage individual experience data items
Ability to globalize the content (to support multiple languages)
Ability to customize workflows (think SME review approval, regulatory, even legal approval) on a per-experience item basis
Ability to mark up each experience item with additional metadata both for cognitive processing purposes and for deployment purposes
All of this content is then exposed to REST services, so you get the ability to integrate automation to bridge the content into the cognitive models
It’s often said that if you design your data structures properly, the rest of your application will practically build itself. This is no exception. While you will have to build your own automation to bridge the gap between your CMS and your cognitive model environments, you’ll be able to do this easily using REST services.
While you may need to come up with your own granularity, you’ll probably find some clear hits, especially in the area of QnA Maker… every Question / Answer experience pair probably fits nicely as a single content entity. You’ll probably have to add metadata to support QnA maker’s filtering, and the like.
Likewise with LUIS, you may find that each Intent and the related utterances is a single content entity. LUIS, being more sophistocated, will also need related entities and synonyms modeled in content data.
I’ve seen other CMS system used. Most notably CosmosDB and Contentful. Another choice might be some kind of data mart. All of these cases require a heavy investment in building out a UI layer for your SMEs. SharePoint takes care of the bulk of that part for you.
Got a project you want to start working on? Don’t forget to account for content management early on. As always, reach out to me if you need advice on this or any other aspect of building out a solution involving technologies like these… Connect on Twitter, Linkedin or the like…
Unfortunately, you’ll quickly discover that with that change, there’s a breaking change in code that requires _more_ than just upgrading nuget packages. (You must update all your nuget packages… in fact, be careful, because some of the new dependencies are out of date… so keep updating until everything is flush)
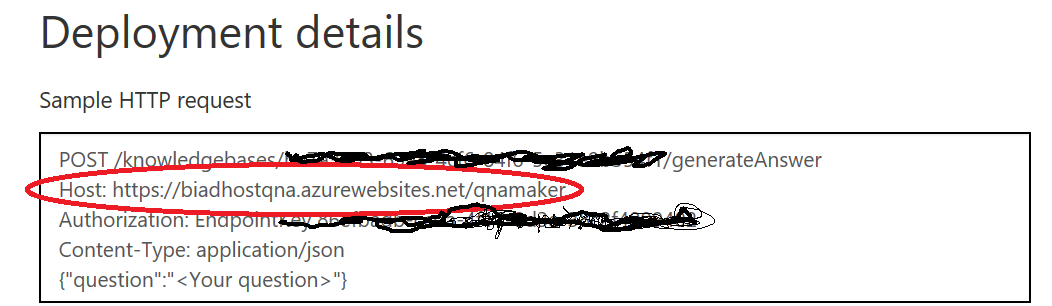
In the live era of QnAMaker, you must also contact the correct host.
After you’ve re-published your migrated knowledgebase in the live environment, you’ll see the familiar deployment details. Among them will be one new detail, that host name:
This changes what you have to pass in to the constructor for the QnAMakerService in your code.
The way the Bot in a Day Workshop lab sets up configuration is via web.config. In your bot project, you’ll need to add a new configuration key to the configuration/appSettings section of the file.
Once you’ve done that, you’ll need to provide the parameter to the constructor of the QnAMakerService… see the example below.
Global Azure Bootcamp 2018, held at over 280 locations around the world on Saturday, April 21st, 2018 is in the books.
These are exciting times. When Microsoft airs commercials that point out that “there is more computing power at your fingertips than in past generations”, I think that’s a severe understatement. There’s more computing power at your fingertips today than there has ever been, over the cumulative course of human history.
Further, Microsoft has never been more clear about their commitment to Azure, to the point of burying Windows within their own organization. It’s not that Windows is gone, it’s that Windows is merely a client to Azure, and their new organization structure reflects this.
I was mostly focused on the Granite State event location, and had my hands full with that… though I did assist the Burlington / Boston event as well, especially getting local sponsorship in the form of custom t-shirts from Insight/BlueMetal.
Thanks so much to all the folks who contributed to make it happen… Peter Lamonica of Manchester Community College for making the facilities available to us… Carl Barton, Xamarin MVP, Roman Jaquez, Patty Tompkins, Marie Patrick in the Granite State (New Hampshire) community for presenting, and Patrick El-Azem, Dave Stampfli, Bret Swedeen, and Gino Filicetti from Microsoft itself, for presenting, and taking the content up a notch. All helped organize the event.
The event really was perfect for the Granite State Users Groups, LLC, an organization I created several years ago specifically to enable users groups to plan events and manage their own resources in the process.
We shared a lot of learning!
Topics included
Azure 101
Azure Functions
Lift & Shift
App Services
Azure Resource Management
Azure Networking
Bot Framework
Cognitive Services
Azure DevTest Labs
SQL on Azure
Azure IoT Hub
All of the support from Global Azure Bootcamp central made some of the harder parts easy… in particular setting up lunch, and providing sponsorship for things like $300 Azure passes and the like.
In retrospect, we had a few minor misses:
We didn’t print up schedules for everyone, which was a mistake. We had enough to effectively share, but should have just printed out a copy for everyone.
We had coffee, but it didn’t arrive till near end of day.
We didn’t take enough photos. 🙂
Azure Passes!
Manchester Community College floor plan
Jetbrains stickers
The “Go-kit” turned into a stack of boxes.
Custom event tshirts from BlueMetal/Insight
Our schedule, with some marked up for specific rooms
Locked & loaded early, ready to roll.
Schedule on display
Our 3rd classroom was a bit remote from the rest of the event.
Carl Barton presenting Azure Functions in session 1.
Panorama of Carl’s session
The school MPR in panorama, rolling with Patrick El-Azeem’s Azure 101, just one of several sessions rolling at the time.